

はじめに
この記事では、Google ColabratoryでBigQueryとPythonを連携する方法を分かりやすく解説します。BigQueryはGoogleのフルマネージド型データウェアハウスで、Pythonと組み合わせることで強力なデータ分析や業務効率化が実現できます。
何が出来るのかを簡単に述べると以下のようなことが出来ます。
- BigQuery上のデータをSQLで指定してPandasデータフレームに変換
- 複数のSQL文をPythonのループ処理などで一気に回す
- Pythonで前処理などを施したデータをPython上でBigQueryにアップロード
以上のようなことが出来るようになります。
これはごく一部ですが、アイデア次第では出来ることは無限にあるのではないでしょうか?
この記事では、私がPython × BigQueryの連携方法とよく使用する使い方をいくつか紹介できればと考えています。
全体像 ⇒ 連携方法の詳細な手順解説 ⇒ 具体的な使用例の紹介
以上のような流れで説明を行っていきます。
Python×BigQueryの全体像と概念の理解
まずは全体像を理解しましょう。
ざっくり以下のような流れです。流れを大体理解した上で細部の説明に行きましょう!
この時点で全て分からなくてもよいので、全体像を把握してください。
- BigQuery側のPythonと連携するための設定をオンにする
- BigQuery APIを有効にする
- PythonでBigQueryを操作するために認証情報を取得
- クライアントを作成するための鍵を作成
- これが無かったら誰でもあなたのBigQueryのデータを処理できることになりますよね
- Python上で取得した認証情報を使ってBigQueryと連携するコードを実行
- ここで2で作成した鍵を使ってBigQueryと連携する準備を完了します。
- Python上でBigQueryを操作!
続いて、BigQueryの説明上で扱う概念の説明です。
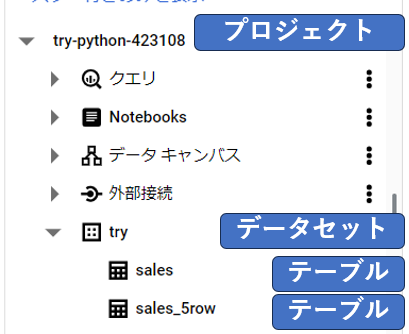
プロジェクト > データセット > テーブル
この3つの関係を把握しておいてください。
プロジェクトの中にデータセットが作られ、データセットの中にテーブルが作られるイメージです。
BigQuery上の画面で確認すると以下のような形になります。
BigQueryAPIの有効化
まずはBigQueryAPIを有効化する必要があります。Google Cloud ConsoleでBigQueryAPIを有効にしてください。
1.BigQueryのコンソール画面にアクセス

Pythonにて操作したいプロジェクトを選択した状態でここからの操作は行ってください。
プロジェクトの選択は左上の三つのtry-pythonと書かれている箇所から行えます。

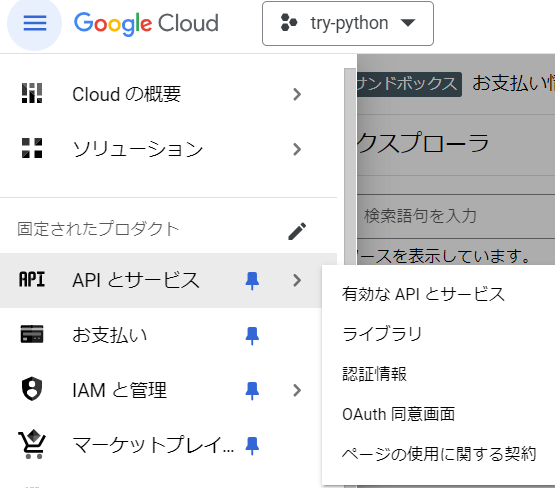
2.BigQuery APIの有効化
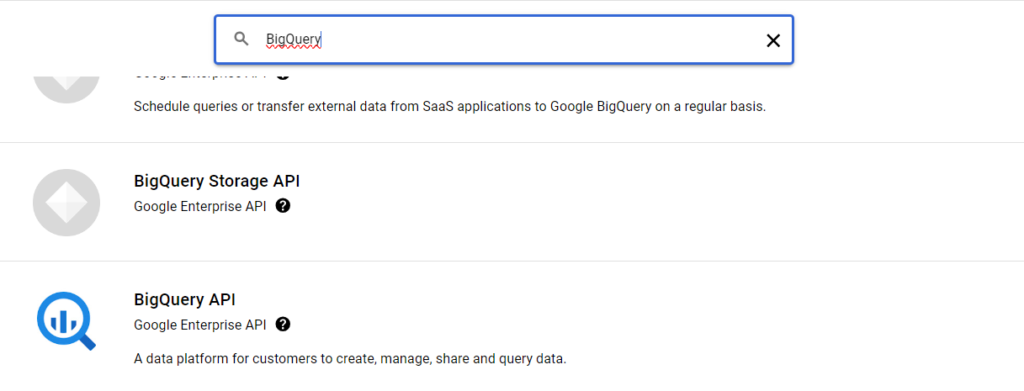
左上のタブからAPIとサービス>ライブラリを選択してください。
その後検索窓でBigQueryと打ち込んで検索してください。「BigQuery API」と書かれたものを選択して有効化ボタンを押してください。APIが有効ですと表示されていたら成功です。
PythonでBigQueryを操作するための認証情報となる鍵の取得
ここからはPythonからBigQueryにアクセスするために必要な認証情報となるファイルをダウンロードします。
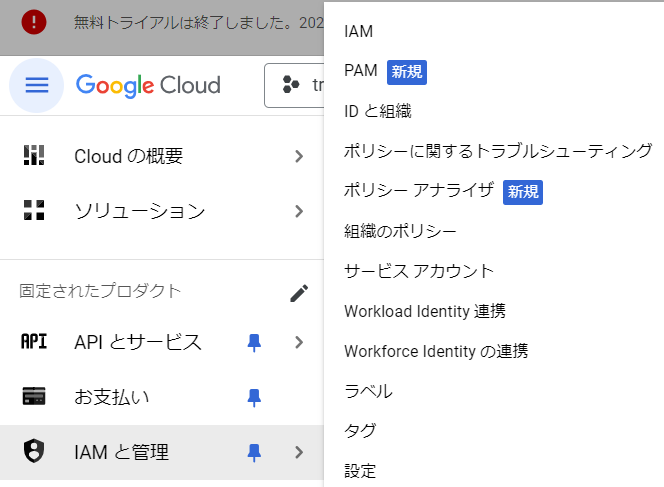
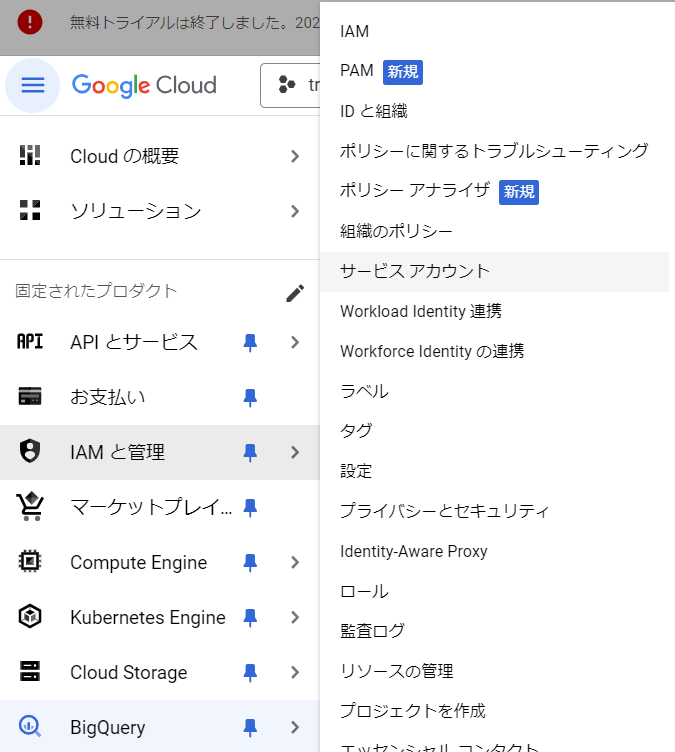
1.サービスアカウント作成
左上のタブからIAMと管理>サービスアカウントと進みます。
サービスアカウント作成を選択

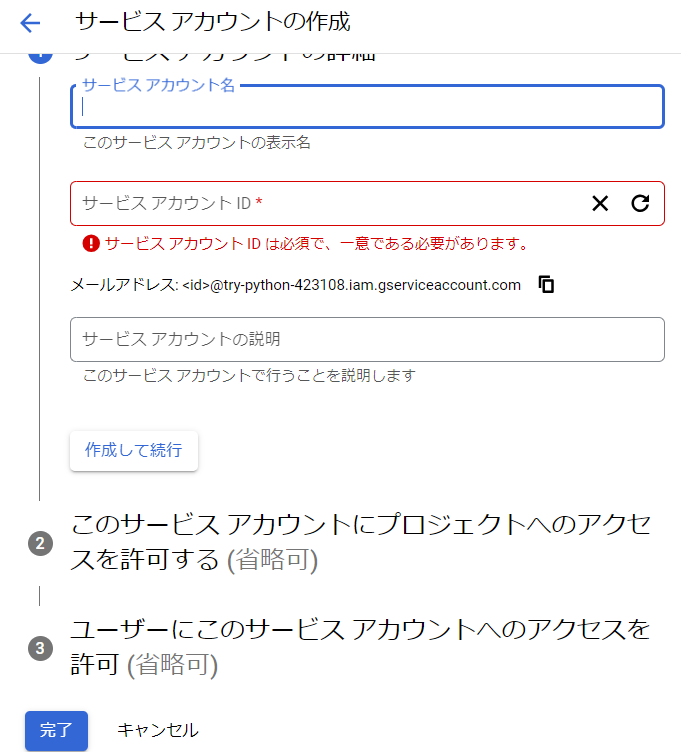
サービスアカウント作成を行います。
そして、サービスアカウント名を自分で好きにつけてください。他は変更しなくても大丈夫です。
完了を押してください。
これでPythonであなたの指定したプロジェクトにアクセスするためのアカウントが作成されるイメージです。
2.鍵の作成
作成したサービスアカウントの操作タブから鍵を管理を選択してください。
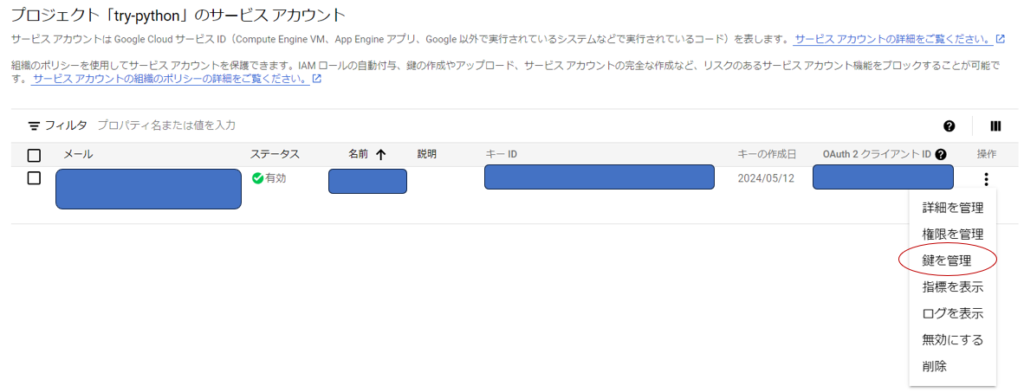
鍵の追加を選択して、新しい鍵を作成を押してください。

その後はJSONを選択して、作成ボタンを押してください。
すると、ファイルがダウンロードされると思います。これで完了です!
このダウンロードされたファイルを後にPythonでの操作時に使用します。
Python, Google Colaboratoryでクライアントの指定
クライアント(Client)って何なのだろう?と思いますよね、、
私もうまく説明できそうになかったため、生成AI(Claude3)に聞いてみました。

分かりやすいですね!
クライアントを定義することでそのクライアントを介してBigQueryとPythonをつないでくれるイメージですね
では、実際にクライアントの指定を進めていきましょう
1.Googke Colaboratoryを開く

2.認証のための鍵ファイルのアップロード
さきほどダウンロードした鍵をアップロードします。
ドライブとマウントするなどお好みの方法でアップロードしてください。
これで準備は完了です!
3.クライアントの指定(ログインのようなもの)
以下のコードを実行してください。
JSONファイルのパスは、アップロードしたファイルのパスをコピーして貼り付ければ確実です。
このコードでは、認証情報であるJSONファイルを渡すことで自分のBigQueryの指定したプロジェクトを操作するためのログインを行っていると考えればよいでしょう。
※google.cloudがインストールされていない場合は, pip install google.cloudを実行してください
import os
from google.cloud import bigquery
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'アップロードしたJSONファイル名のパス’
client = bigquery.Client()これでクライアントの指定の完了です。
これでPythonでBigQueryの操作を行う準備が全て完了したので実際に操作をしていきましょう!
操作の全体像
BigQueryでは先ほど説明したようにプロジェクト、データセット、テーブルの3つの階層構造でデータを管理します。Python側からは主に以下のような流れで操作を行います。何をするかによって最後の箇所が異なりますが流れとしては以下のような流れで進めていきます。
- プロジェクトID,データセットID、テーブルIDを指定
- クライアントにクエリを渡して実行
- 結果を取得
- 取得した結果への処理を指示
各操作のサンプルコード
1.テーブルをデータフレームで読み込む(SQL文を直接記述)
SQL文のみ変更すれば活用できます。
# from google.cloud import bigquery
# client = bigquery.Client()
sql = """
SQL文をBigQueryのコンソールと同じように記述
"""
df = client.query_and_wait(sql).to_dataframe()2.テーブルをデータフレームで読み込む(SQLファイルを作成し、それを実行する)
SQLファイルを準備した上で、そのSQL文を BigQuery上で実行したいことを考えます。
SQLファイル(sample.sql)を用意したことを想定しています。
pathのみ変更いただければ活用できます。
# import pandas as pd
# import pandas_gbq
# client = bigquery.Client()
# クエリ
path = 'sample.sql'
try:
with open(path, 'r', encoding='utf-8') as f:
sql = f.read()
except Exception as e:
raise e
# pandasのread_gqbにて読み込みます。
# dialect='standard'とすることで標準SQLを使用(default='legacy')
df = pd.read_gbq(sql)3.Pythonで加工など行ったデータフレームをBigQueryにアップロード
Pythonにて前処理などを行ったデータフレームをBigQueryにアップロードすることを想定します。
project_id,table_idを変更すると活用できます。
※table_id は[データセット名.テーブル名]となっているので注意
※無料版だと制限にひっかる可能性があるが、有料版であれば問題なし
# import pandas
# import pandas_gbq
# client = bigquery.Client()
# TODO: Set project_id to your Google Cloud Platform project ID.
project_id = ""
# TODO: Set table_id to the full destination table ID (including the
# dataset ID).
# ex) table_id = 'try.sales_5row'
table_id = ''
pandas_gbq.to_gbq(df, table_id, project_id=project_id)おわりに
この記事ではGoogle ColabratoryでBigQueryとPythonを連携する方法について解説しました。是非実際に手を動かしながら学んでみてください。
私が本記事で紹介した活用法は一部なので、ぜひあなたのアイデアで有効に活用してみてください!

コメント